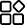一、引言
目前,在分析高光谱数据这样的高维数据时,进行特征波段的提取是非常必要的。首先,提取特征波段可以从原始数据中获取最具代表性和区分性的特征集,从而有效地降低数据的维度,减少存储和计算成本。其次,特征波段的提取可以通过选择与目标相关的波段来减少噪声和冗余的影响,提高数据的准确性和可靠性。关于在田间复杂环境下,高光谱技术如何实现对早期水稻秧苗与稗草精准识别的具体方法及能力,以及利用竞争性自适应重加权采样算法从高光谱数据中高效筛选出对水稻和稗草分类最有效的特征波长方面的研究鲜见报道。本研究以二叶-四叶期水稻秧苗和稗草为研究对象,利用高光谱技术分别获取田间和实验室培育的苗期水稻和稗草的光谱数据,采用CARS筛选出特征波长,利用MATLAB分类学习器工具箱进行种类识别,构建一种高效、准确的早期水稻与稗草分类识别模型,旨在探究水稻秧苗与稗草的早期准确识别方法,以期为农田杂草的精准防控、减少化学除草剂的使用提供科学依据。
二、材料与方法
2.1 材料
以水稻、稗草为研究对象,供试水稻品种为‘农香优204’。试验对象数据采集为秧田直接采集和实验室内培育后采集,田间数据采集地点为湖南省长沙县春华镇张家坊的春华基地(28.29085°N,113.27462°E,海拔73.7m)。根据其生长发育阶段的不同,具体分为二叶期和二叶-四叶期2个样本集,样本数据情况见表1。
表1 样本数据采集信息情况

2.2 技术方法
通过分别采集秧田和实验室培育2种试验条件下的苗期水稻和稗草的高光谱反射率,利用光谱参数构建苗期水稻和稗草快速无损分类模型,并进行模型精度验证(图1)。
2.2.1 试验设计和数据采集方法


图2 实验室培育、田间种植的水稻和稗草的生长情况
田间试验小区的种植密度为22万株/hm2,设置2个小区,每个小区面积180m2,分别种植水稻和稗草。样本进行光谱数据取样时,按照五点取样法,每个取样点12个光谱数据,取样时间分为2次,分别为2023年8月11日和8月15日(10:00—11:30),水稻或稗草的样本量计120个(图2)。2023年8月18日于实验室培养箱中培育水稻和稗草(图2),分别于8月26日、8月31日和9月1日在室外进行光谱数据采集。利用地物光谱仪对早期水稻和稗草样本进行光谱测定,该仪器波段范围是400~920nm。便携光谱仪经白板校准后进行测试,光纤探头置于叶片表面上方20~30mm,探头视场角为25°。试验采用黑色背景以防影响植物的反射率。
2.2.2 光谱数据处理
原始光谱数据采用SG平滑和SG求导进行预处理,对二叶期数据集和二叶-四叶期数据集分别进行SG卷积平滑、SG卷积平滑-SG卷积求导和SG卷积平滑-SG卷积求导-CARS处理。其中,SG卷积平滑的宽口宽度设置为5,SG卷积求导的阶数设置为2,宽口宽度设置为5。
采用竞争性自适应重加权采样算法(CARS)来进行特征波段的提取。CARS的参数设置为:最大主因子数为10,交叉验证次数为10,数据预处理方法设置为“center”,蒙特卡罗采样次数为1000。
2.2.3 建模方法
采用10折交叉验证的方法建立LDA、PLSDA、二次SVM、子空间判别和RBF-SVM模型对稗草和水稻进行分类。基于上述处理后的数据集,进行了校正集和验证集的划分。对于二叶期数据集,从水稻和稗草样品中随机各取20个样品划入验证集中,剩下的79个样品被划入校正集。对于二叶-四叶期数据集,从水稻和稗草样品中随机各取40个
样品划入验证集中,剩下的151个样品被划入校正集。将划分好的校正集作为输入数据结合PLSDA、线性判别、二次SVM、子空间判别、RBF-SVM等建模方法分别建立模型,且对建立的所有模型进行10折交叉验证和外部验证集验证。
在建立分类模型之前,需要先进行参数设置。其中,二次SVM模型有3个参数,分别是核函数、框约束级别和核尺度模式,将其分别设置为“二次”“1”和“自动”。子空间判别模型有集成方法、学习器类型、学习器数量和子空间维度4个参数,将其分别设置为“Subspace”“判别”“30”和“256”。RBFSVM有学习器、扩展维度数、Lambda、核尺度和迭代次数等参数,将其分别设置为“SVM”“16384”“0.006623”“1”和“1000”。
三、结果与分析
3.1 水稻秧苗及早期稗草高光谱特征分析
由图3可知,在700~900nm二叶期水稻的吸收强度略高于稗草,但从光谱曲线趋势来看,水稻和稗草的吸收峰位置大致相同,且曲线相互混杂,无法进行分类。通过主成分分析(PCA)发现,尽管前3个主成分能够解释数据集中97.70%的总方差,有效降低了数据维度,水稻与稗草在PCA得分图上的分布也具有一定的区分趋势,水稻偏右上方(PC2:−10%~20%),稗草偏左下方(PC2:−20%~0%),其重叠与聚集现象仍较为严重,不足以作为直接分类的依据(图3(b))。
二叶-四叶期水稻和稗草在400~900nm波段的吸收光谱特性与二叶期水稻和稗草的光谱特性基本一致,但混杂程度更高(图3(c))。对光谱数据进行主成分分析发现,该时期数据集的聚集程度也高于二叶期数据集(图3(d))。综上,水稻秧苗与稗草在光谱特征上存在重叠,难以直接分类,且随着生长阶段变化,混杂程度增加,需结合多特征参数或高级分类算法以提高分类准确性。
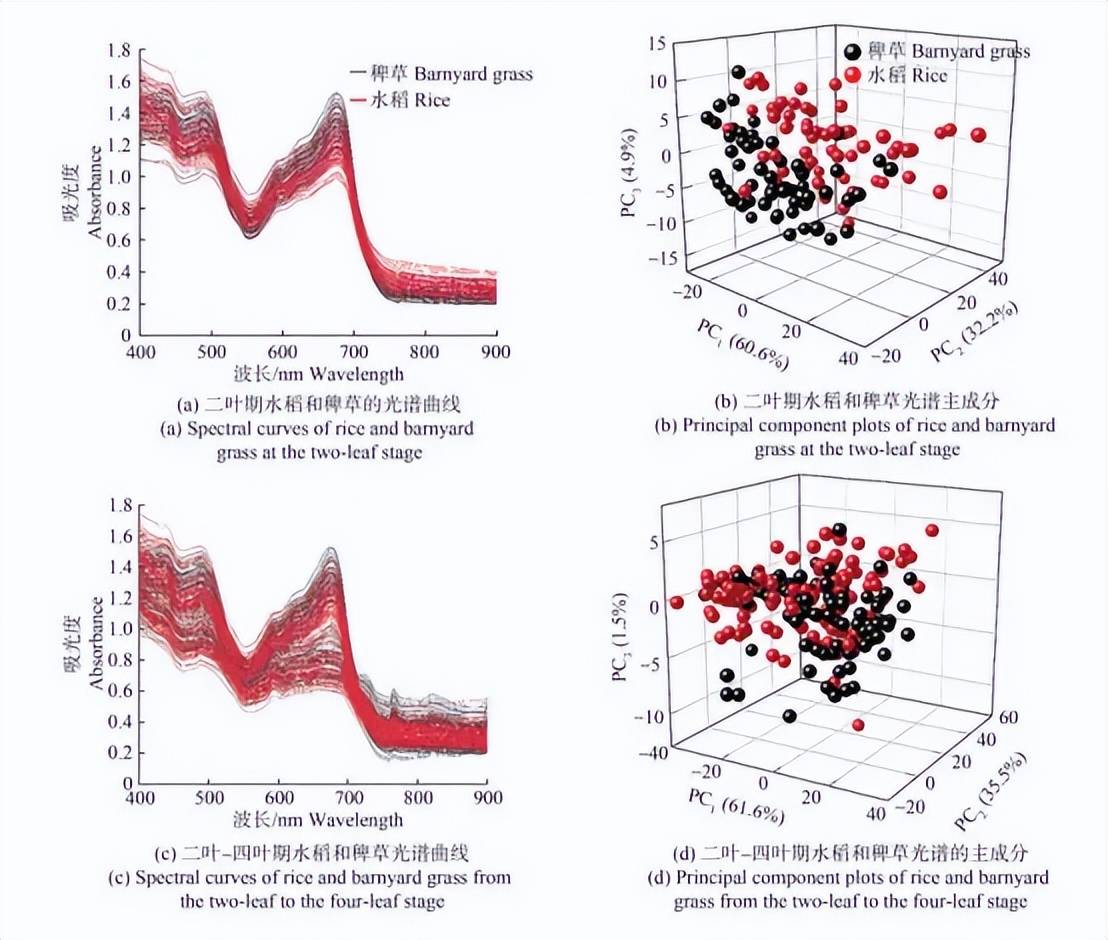
图3 不同时期水稻和稗草的光谱曲线及主成分分析
3.2 光谱数据处理
图4 竞争自适应重加权采样算法(CARS)筛选的特征波长
由图4可知,CARS算法在二叶期和二叶-四叶期数据集选择的特征光谱变量位置大致一致,在二叶期数据集中选择了54个变量,在二叶-四叶期数据集中选中了58个变量,在2个数据集共同选择了12个变量。综上,尽管数据集的时间背景存在差异(一个是二叶期,另一个覆盖了二叶-四叶期)CARS算法仍能有效识别出跨时期稳定的特征光谱波段,意味着这12个共同的变量可能是区分不同水稻和穆草的关键特征波段。
3.3 水稻秧苗及早期稗草识别估测模型的建立及检验
3.3.1 PLS-DA和线性判别分类模型分析
表2 不同处理和建模方法下稗草与水稻的识别准确率
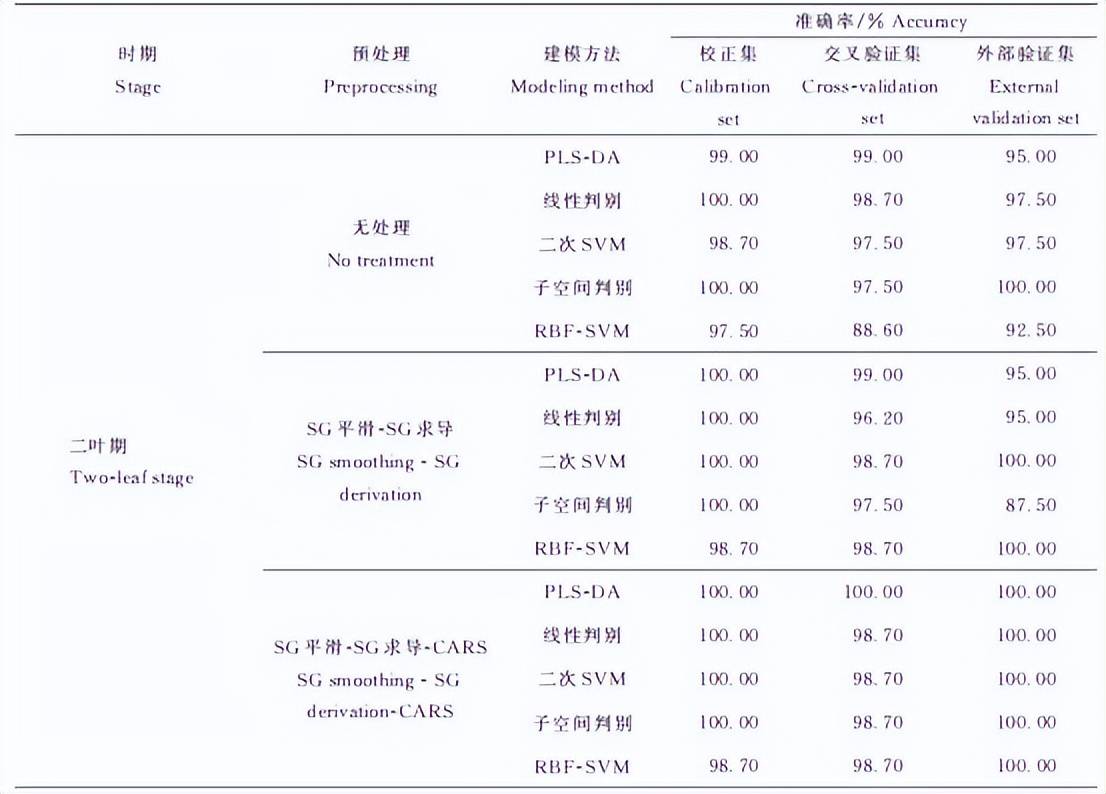
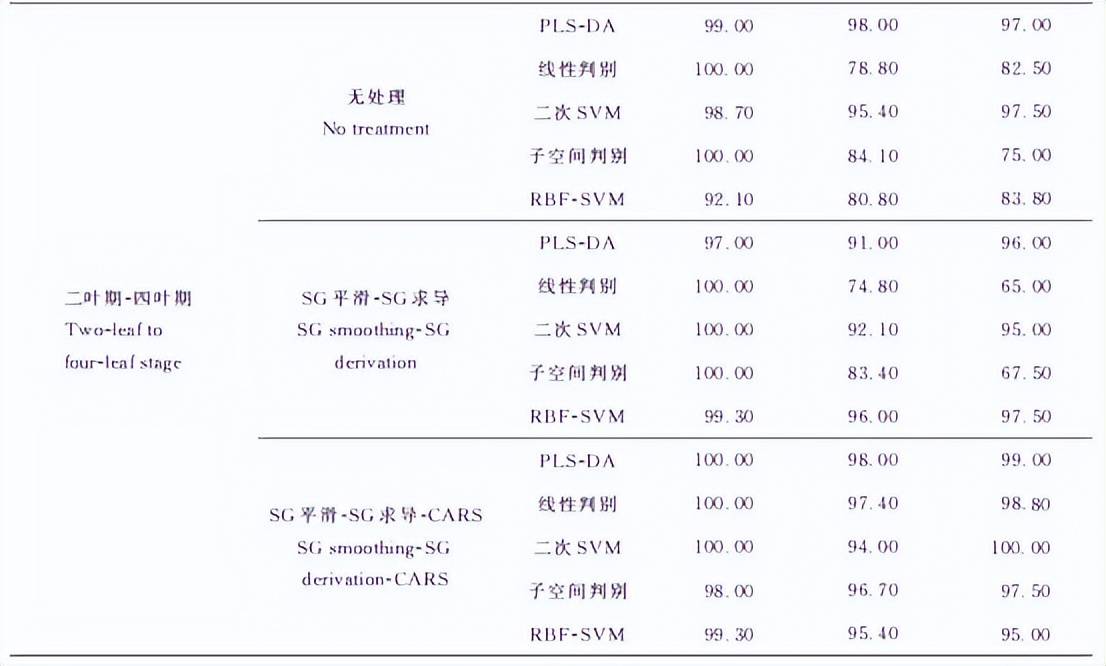
由表2可知,PLS-DA模型中2个数据集中表现最好的是基于SG平滑-SG求导-CARS优化后的模型,其中二叶期准确率在校正集、交叉验证集和外部验证集中都为100.00%,二叶-四叶期数据集校正集、交叉验证集和外部验证集的准确率分别为100.00%、98.00%和99.00%。对于无处理和SG平滑-SG求导建立的模型,其在二叶期数据集中表现一致,在二叶-四叶期数据集中基于无处理所建立的模型效果更好。
基于二叶期数据集建立的线性判别模型性能略低于PLS-DA模型,其中于SG平滑-SG求导-CARS优化后的模型效果最优,校正集、交叉验证集和外部验证集的准确率分别为100.00%、98.70%和100.00%。但在二叶-四叶期数据集中,线性判别模型表现较差,对于无处理和SG平滑-SG求导建立的模型,其交叉验证集的正确识别率仅在75.00%左右。但基于SG平滑-SG求导-CARS优化后的模型,其交叉验证集的正确识别率提升到97.40%,表明CARS算法能够提取有效光谱信息,提升模型的性能。
3.3.2 非线性分类模型分析
在二叶期数据集中,基于SG平滑-SG求导-CARS处理建立的二次SVM模型和子空间判别模型表现最优,二者校正集、交叉验证集和外部验证集的准确率分别为100.00%、98.70%和100.00%(表2)。在二叶-四叶期数据集中,基于SG平滑-SG求导-CARS处理建立的子空间判别模型表现最好,其校正集、交叉验证集和外部验证集的准确率分别为98.00%、96.70%和97.50%。但子空间判别在无处理和SG平滑-SG求导处理的数据集中的交叉验证集中的正确识别率为84.00%左右,低于二次SVM和RBF-SVM建模方法。
四、讨论
本研究应用高光谱技术于稻田稗草的早期识别,为除草机器人的精准作业提供了有力的决策支持,是实现农业变量施药、精准除草策略的关键一步。研究表明,705nm是区别水稻和稗草的特征光谱波长,本研究中使用的CARS算法在两类数据集都在705nm附近进行变量选择,这更加表明CARS算法能够成功的提取区分水稻和稗草的特征光谱变量。采用低成本的地物光谱仪,结合特征光谱筛选算法,成功构建高敏感性的稻田稗草识别模型,该模型在二叶期达到100.00%的识别准确率,在二叶-四叶期也保持98.00%的高精度,相较于利用图像识别技术获得的识别准确率范围在91.01%~97.48%,本模型展现出更为优越的性能。这不仅证明了光谱技术在杂草识别中的有效性,也凸显了其在提高农业生产效率方面的巨大潜力。
与图像识别技术相比,光谱识别技术以其较低的时间成本具有更大的应用潜力。研究中采用的人工光谱数据采集方式保证数据的准确性,但其耗时费力的问题限制了在大面积稻田中的广泛应用。因此,未来的研究应聚焦于开发高效的数据采集系统,如引入无人机或田间自主移动机器人,以实现光谱数据的快速、实时获取与分析,从而加速稻田稗草识别与施药过程的智能化集成。此外,高光谱数据在采集过程中易受多种噪声源干扰,这些噪声不仅降低了数据质量,也影响了后续建模的准确性和可靠性。针对这一问题,本研究均强调了数据预处理的重要性,包括平滑、求导和散射校正等措施对减少或消除噪声、提升数据质量具有显著效果。
然而,随着应用环境的复杂化,如何进一步优化预处理算法,以适应不同条件下光谱数据的处理需求,仍是下一步研究的重要方向。
五、结论
利用高光谱技术结合多种分类算法对二叶-四叶期水稻和稗草的叶片光谱数据进行识别分析发现,SG平滑-SG求导结合CARS预处理再结合PLS-DA算法在提升模型识别精度和稳定性方面表现最优,可显著提升二叶-四叶期水稻和稗草识别模型的交叉验证和外部验证的正确率,分别高达98%和99%,尤其在水稻二叶期单一时期的样本集上,无论是校正集、交叉验证集还是外部验证集,均实现100%的识别率,该模型充分验证其在水稻二叶期数据建模中的高效性和准确性,可应用于水稻早期田间稗草识别和防除。